
New cache hierarchy offers more speed and reduces power requirements
July 18, 2017
on
on
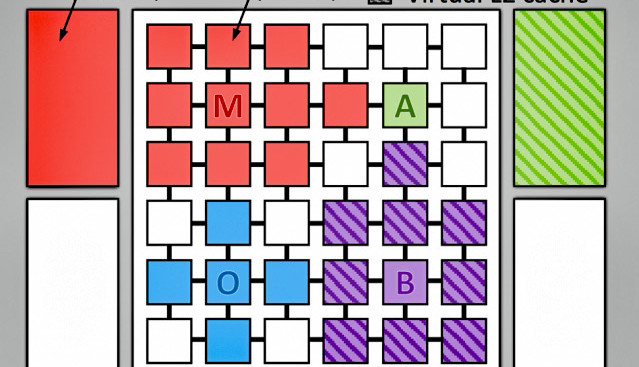
Researchers at MIT’s Computer Science and Artificial Intelligence Laboratory have simulated a memory cache system called "Jenga" that creates new cache structures on the fly to optimize memory access for each specific app. This new approach is said to offer increased processing speed by up to 30% with otherwise identical hardware and to reduce energy consumption by up to 85%.
Cache memory is a standard feature of computer architecture to help boost processing speed. Modern processors usually feature three or four levels of cache memory. The level closest to CPU operation will have the fastest access time but smallest capacity while each level farther from the CPU will have greater capacity but slower access times. The Intel Pentium 4, for example, came with two L1 caches, each with 8 KB and an upstream L2 cache of 256 KB. A more recent i7, on the other hand, has a separate 32 KB L1 cache for instructions and data as well as an additional L2 cache of 256 KB clocked at the processor speed plus a slightly slower L3 cache of up to 20 MB for all cores. Extreme design strategies are necessary to boost processing power without bumping up the clock speed but they take up a lot of space on the die. These measures are therefore expensive and increase power consumption, its worth remembering that little more than 20 years ago a standard PC had less main memory available than today’s CPU L3 cache!
The MIT researchers have been busy looking for alternative strategies to provide processing acceleration. This new memory organisation approach called Jenga, was tested on a simulated processor with 36 cores using a massive (1 GB) configurable L3 cache. The L1 and L2 caches were considered private and allocated as usual to the individual cores. The key difference with this system is that the L3 cache is allocated ad hoc. As code executes Jenga is able to build virtual hierarchies tailored to each application running on the system. It knows the physical locations of each memory bank and can calculate how to store data to optimize access time, even if that requires a change to the memory hierarchy. The result is not only an increase in code execution by 20 to 30%, but also an energy saving of 20 to 85%, since the need for unnecessary internal operations is significantly reduced.
The report can be downloaded as a PDF file.
Cache memory is a standard feature of computer architecture to help boost processing speed. Modern processors usually feature three or four levels of cache memory. The level closest to CPU operation will have the fastest access time but smallest capacity while each level farther from the CPU will have greater capacity but slower access times. The Intel Pentium 4, for example, came with two L1 caches, each with 8 KB and an upstream L2 cache of 256 KB. A more recent i7, on the other hand, has a separate 32 KB L1 cache for instructions and data as well as an additional L2 cache of 256 KB clocked at the processor speed plus a slightly slower L3 cache of up to 20 MB for all cores. Extreme design strategies are necessary to boost processing power without bumping up the clock speed but they take up a lot of space on the die. These measures are therefore expensive and increase power consumption, its worth remembering that little more than 20 years ago a standard PC had less main memory available than today’s CPU L3 cache!
The MIT researchers have been busy looking for alternative strategies to provide processing acceleration. This new memory organisation approach called Jenga, was tested on a simulated processor with 36 cores using a massive (1 GB) configurable L3 cache. The L1 and L2 caches were considered private and allocated as usual to the individual cores. The key difference with this system is that the L3 cache is allocated ad hoc. As code executes Jenga is able to build virtual hierarchies tailored to each application running on the system. It knows the physical locations of each memory bank and can calculate how to store data to optimize access time, even if that requires a change to the memory hierarchy. The result is not only an increase in code execution by 20 to 30%, but also an energy saving of 20 to 85%, since the need for unnecessary internal operations is significantly reduced.
The report can be downloaded as a PDF file.
Read full article
Hide full article
Discussion (0 comments)